Yield
The robot waits in a nearby parking cell and resumes after the conflict clears. Cost: 1 IU.
A hybrid, information-centric multi-agent path finding framework that minimizes sensing and communication overhead through conflict-driven coordination and tiered replanning.
Multi-Agent Path Finding (MAPF) is central to coordinating multiple agents in shared environments. Existing solutions impose significant requirements on communication, sensing, and computation, limiting their applicability in resource-constrained robotic deployments. Centralized search methods require full access to global state information and high-bandwidth channels, while distributed learning-based methods depend on sophisticated onboard perception (e.g., LiDAR, RGB-D cameras) and frequent inter-agent communication.
To address these limitations, we formulate Information-Centric MAPF (I-MAPF) and introduce HI-MAPF, a hybrid framework that augments decentralized planning with a lightweight centralized coordinator. We further introduce a method-agnostic metric, Information Units (IU), to quantify coordination overhead as a proxy for deployment cost. We evaluate HI-MAPF against recent communication-focused algorithms in both simulation (8–128 agents across structured and unstructured environments) and on ground robots in a physical deployment, demonstrating 2× to 510× reduction in information sharing while maintaining high success rates.
We characterize MAPF coordination by the information available to each agent \(i\) at time \(t\):
Different MAPF paradigms differ in how much of \(\mathcal{I}_i(t)\) each agent accesses: Centralized methods use global \(\mathcal{M}\) and all agents' trajectories. Distributed methods restrict \(\mathcal{M}_i\) to a local FOV and \(\mathcal{O}_j\) to neighbors. Hybrid methods (including HI-MAPF) selectively reveal \(\mathcal{O}_j\) and constraints in response to \(\mathcal{E}_{ij}(t)\).
To enable principled comparison of information consumption across MAPF paradigms, we define:
Lower IU indicates lower bandwidth, energy, and onboard hardware burden, improving feasibility for long-term robotic deployment. A \(d\)-dimensional inter-agent message vector (e.g., SCRIMP's 512-dim messages) contributes \(d\) IUs per transmission.
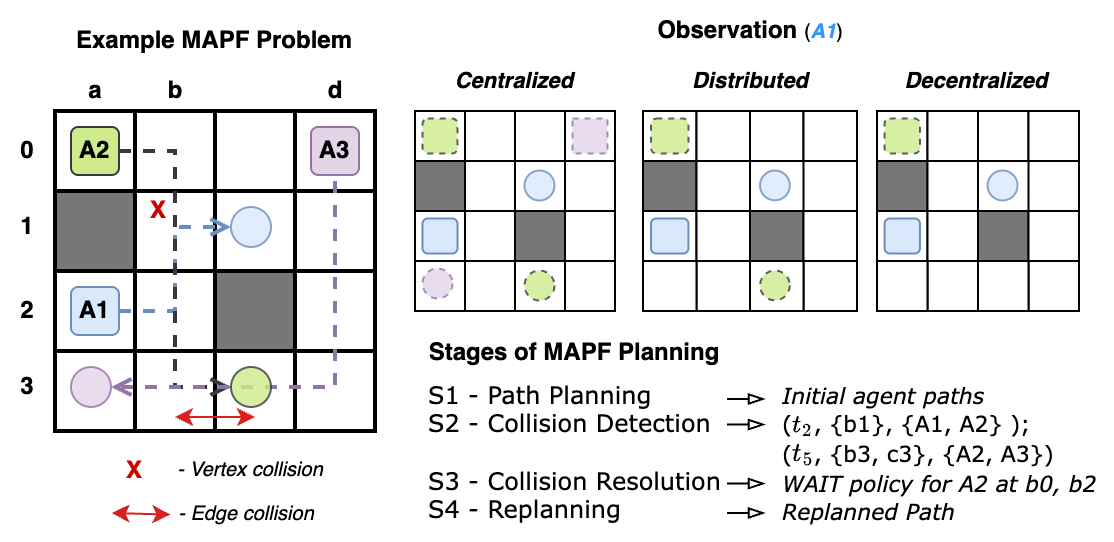
HI-MAPF operates as a four-stage pipeline that iterates until all conflicts are resolved:
The replanning stage itself is tiered. Lower-cost modes are tried first, so the more expensive coupled repairs remain available without becoming the default behavior.
The robot waits in a nearby parking cell and resumes after the conflict clears. Cost: 1 IU.
The conflict region is treated as a temporary obstacle during bounded replanning. Cost: \(|\Delta c|\) IUs.
Short trajectory fragments are shared as time-indexed obstacles. Cost: \(r\) IUs.
Tightly coupled agents are replanned together over a local window. Highest cost, rare use.
The interactive view below shows the same escalation policy visually. Each mode reveals only the amount of information needed for that repair tier to succeed.
The four repair modes below show the same story visually: start cheap, reveal only what the repair needs, and escalate only when the lower tier cannot resolve the conflict.
Across all simulated benchmarks (8–128 agents), the vast majority of conflicts are resolved at the cheapest tier:
Usage share across all benchmarks. Achieves 91–99% success rate.
Usage share across all benchmarks. Achieves 99–100% success rate.
Usage share across all benchmarks. Achieves 11% success rate.
Usage share across all benchmarks. Achieves 72–100% success rate.
We validated HI-MAPF on a five-robot TurtleBot4 testbed laid out as a six-by-six grid. The goal was to see how much information each method had to reveal in order to finish the same coordination task.
HI-MAPF recorded the lowest total information usage in the physical deployment.
Lowest average makespan among the evaluated hardware baselines.
Five TurtleBot4 robots executed the deployment tests in a six-by-six grid.
SCRIMP used 42,413 IU on the same hardware task, making the gap easy to see.
| Algorithm | Success Rate | Avg Makespan | Total IU | IU Multiplier | Exec Time (s) |
|---|---|---|---|---|---|
| HI-MAPF | 100% | 12.2 | 199 | 1.0x | 181.5 |
| MAPF-GPT-2M | 100% | 13.6 | 588 | 3.0x | 176.2 |
| DCC | 100% | 19.4 | 596 | 3.0x | 235.0 |
| EPH | 100% | 21.8 | 623 | 3.1x | 234.9 |
| SCRIMP | 100% | 16.4 | 42,413 | 213.0x | 211.2 |
The physical deployment complements the summary table with direct evidence from the testbed: robot layout, benchmark outcome snapshots, and a short hardware run video.

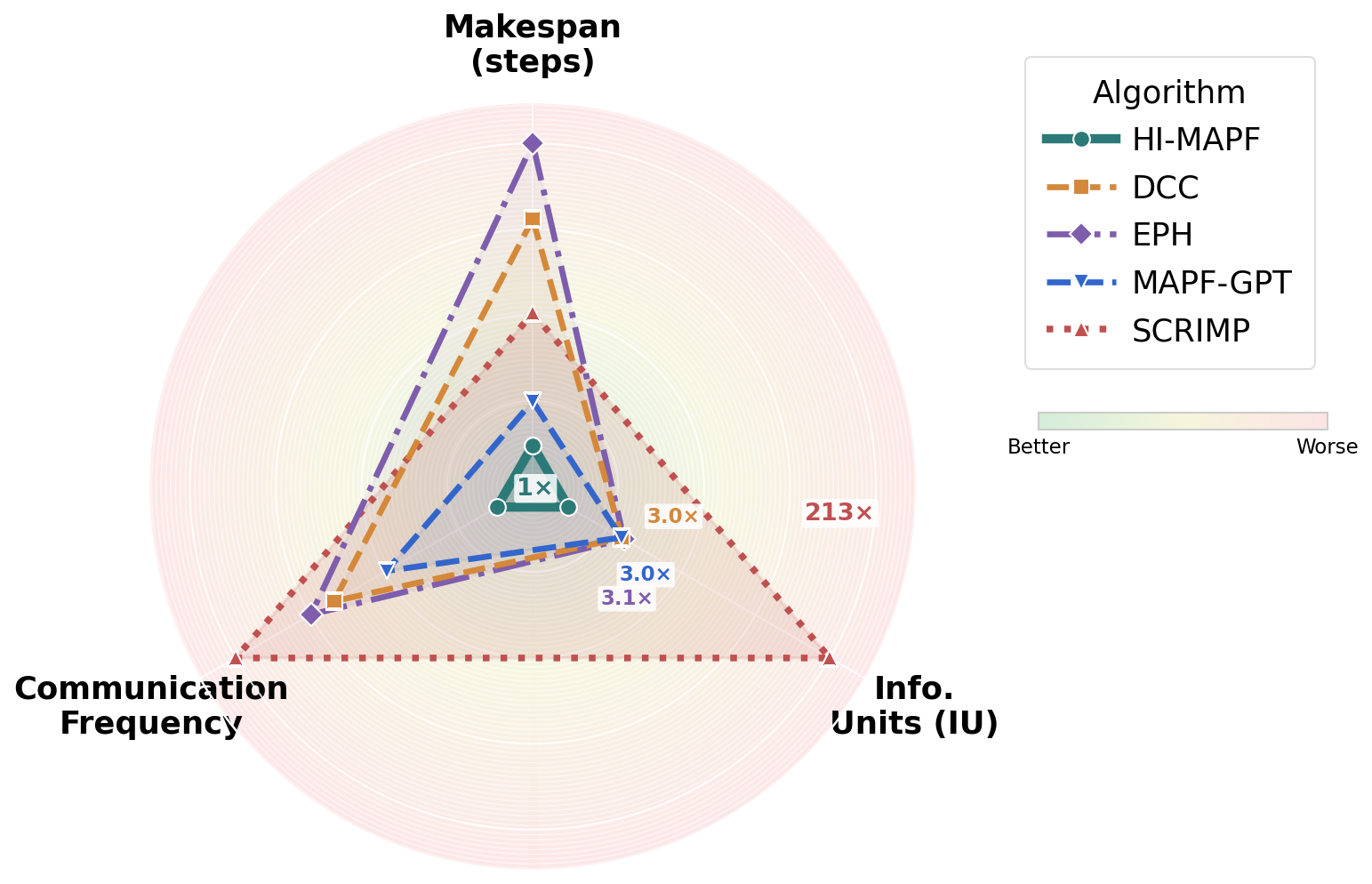
IU dominated by initial map broadcast (71%), with remaining IU from conflict-triggered constraints during replanning. No onboard perception required.
99% of IU from 512-dim inter-agent messages transmitted via transformer-based communication module at every timestep.
IU dominated by per-timestep position broadcasts and action transmissions (49–53%), with FOV sensing contributing ~20–22%.
Competitive makespan (13.6) but requires 11×11 FOV observations (~41% of IU) compared to 3×3 in SCRIMP.
The simulation suite used four benchmark maps and compared HI-MAPF against learning-based and hybrid baselines across agent counts from 8 to 128. The chart selector summarizes the main trends without forcing the reader through a wall of raw numbers.